1. 什么是插入排序
插入排序(Insertion Sort) 是我们日常生活中最不自觉就会用到的排序算法。它的核心思想可以用一句话概括打扑克牌时的理牌动作。
想象一下你正在打斗地主,你左手拿着已经理好的牌(已排序部分),右手从桌上抓起一张新牌(未排序元素)。你会从右往左依次对比手里的牌,找到合适的位置,把新牌插进去。插入排序就是这么工作的!
其实重点就是,如何去组织⬇️
- 有序区域
- 无序区域
那么谁能保证我每一次都能前面拿到的都是有序呢?那么我们就默认你的第一张就这个独苗她就是有序的!
也就是说第一次你假定[4]就是有序区。
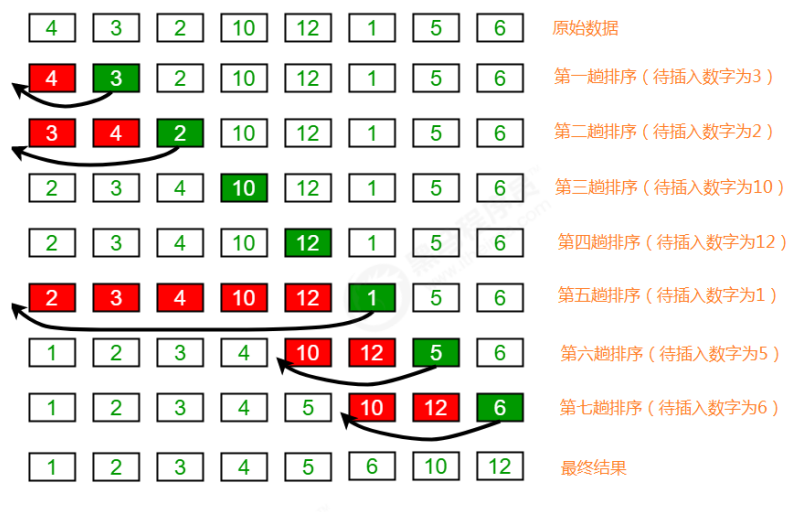
2. 代码实现
直接上代码实现会比较好点。下面2种写法是一模一样的,如果你能搞懂下面2种写法的不一样的地方,那么插入算法你就懂了。
# 写法1
def insertion_sort(arr):
n = len(arr)
for i in range(1, n):
key = arr[i]
j = i - 1
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
# 写法2
def insertion_sort(arr):
n = len(arr)
for i in range(1, n):
key = arr[i]
j = i
while j > 0 and arr[j - 1] > key:
arr[j] = arr[j - 1]
j -= 1
arr[j] = key
return arr
# 测试
data = [29, 10, 14, 37, 13]
print(f"排序后: {insertion_sort(data)}")
代码难点必须看!
如果上面的区别你看不懂,你就很难学习接下来的概念,包括希尔排序。
# 视角 1:j 是“坑”的位置
def insertion_sort_v1(arr):
n = len(arr)
for i in range(1, n):
key = arr[i]
j = i # 👈 j 一开始就指向我们要腾出来的“坑位”
# 只要坑位前面还有牌 (j > 0),且前面的牌比 key 大
while j > 0 and arr[j - 1] > key:
arr[j] = arr[j - 1] # 前面的牌往右边(现在的坑位)挪
j -= 1 # 坑位往左移了一格
arr[j] = key # 循环结束,当前的 j 就是最终的坑位,直接放进去
return arr
- 逻辑核心:我盯着这个**“空位”**。如果前面的数比我大,我就把前面的数拉到这个空位里,然后空位就自然转移到了前面(
j -= 1)。最后把key填进这个空位arr[j]里。 - 优点:最后那一步
arr[j] = key看起来非常自然,不需要加一。
这是你写的第二个版本(写法 1):
# 视角 2:j 是“正在比较的牌”的位置
def insertion_sort_v2(arr):
n = len(arr)
for i in range(1, n):
key = arr[i]
j = i - 1 # 👈 j 指向左手已经排好序的最后一张牌
# 只要手里还有牌 (j >= 0),且手里的牌比 key 大
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j] # 把这张牌往右挪一格
j -= 1 # 手往左边摸下一张牌
arr[j + 1] = key # 👈 因为刚才 j 多减了 1,所以真正的空位在 j + 1
return arr
- 逻辑核心:我盯着**“左手里的牌”**。只要这张牌比
key大,我就把它往右边推一格(arr[j + 1] = arr[j]),然后我的目光看向左边一张牌(j -= 1)。 - 你的疑惑解答:你在注释里写的
# 因为这里减去了 所以要加完全正确!当while循环因为arr[j] <= key停下来时,j指向的是那张比 key 小的牌。所以,key当然要插在它后面,也就是j + 1的位置。
| 特性 | 第一种写法 (j = i) | 第二种写法 (j = i - 1) |
|---|---|---|
j 的意义 | 坑位(空位)所在的位置 | 正在进行比较的元素位置 |
| 越界保护 | j > 0 (因为我们要查 arr[j-1]) | j >= 0 (因为我们要查 arr[j]) |
| 落子位置 | arr[j] = key | arr[j + 1] = key |
哪个更好?
在实际工程中,这两种写法的性能是完全一模一样的,底层的机器指令也几乎没有区别。全凭程序员的个人喜好。
- 有人喜欢第一种,因为
arr[j] = key看着更整洁,不用烧脑去想+1的问题。 - 有人(包括很多教科书)喜欢第二种,因为
j = i - 1更符合“拿当前牌和前面所有牌比较”的直觉语言。
3. 优化写法
插入排序在处理小规模或基本有序的数据时已经非常强悍了,但它依然有两个痛点:
- 找位置慢:需要挨个往前比较(比较次数多)。
- 挪位置慢:如果遇到极端的逆序(比如
[9, 8, 7, 1]),那个1要从最后一位一点点平移到第一位(移动次数多)。
二分法 Binary Insertion Sort
前面我们讲过,左手里的牌已经是排好序的。既然是有序数组,我们凭什么还要“从右向左挨个看”?直接上**二分查找(Binary Search)**啊!
普通插入排序是:找位置 O(n),挪位置 O(n)。
折半插入排序是:找位置 O(log),挪位置 O(n)。
def binary_insertion_sort(arr):
n = len(arr)
for i in range(1, n):
key = arr[i]
# 1. 用二分查找在 [0, i-1] 的有序区间里找插入位置
left, right = 0, i - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] > key:
right = mid - 1 # key 比较小,去左半边找
else:
left = mid + 1 # key 比较大(或相等),去右半边找
# 循环结束后,left 的位置就是 key 应该插入的正确位置!
# 2. 批量往右平移腾出坑位 (从 i-1 挪到 left)
for j in range(i - 1, left - 1, -1):
arr[j + 1] = arr[j]
# 3. 填坑
arr[left] = key
return arr
# 测试
data = [37, 23, 0, 17, 12, 72, 31, 46, 100, 88, 54]
print(f"折半插入排序后: {binary_insertion_sort(data)}")
局限性:虽然比较的次数大幅减少了,但数组元素的平移次数并没有减少。所以它的最坏时间复杂度依然是 O(n^2)
希尔排序 Shell Sort
如果说折半插入排序是小修小补,那希尔排序就是对插入排序的降维打击。
插入排序的致命伤是:元素只能一步一步地挨个换。如果最小的数在最右边,它要挪 n-1 次才能到最左边。
希尔排序的逻辑是:步子迈大点! 我们先让间隔为 gap 的元素跨越式地进行插入排序,把大数迅速丢到后面,小数迅速拎到前面。然后再缩小 gap,直到 gap = 1(此时就是标准的插入排序)。
def shell_sort(arr):
n = len(arr)
gap = n // 2 # 初始步长,每次砍半
# 只要步长大于 0,就继续分组排序
while gap > 0:
# 下面这就是一个稍微修改了间隔的“插入排序”
for i in range(gap, n):
key = arr[i]
j = i
# 以前是 j - 1,现在是 j - gap;以前挪 1 步,现在挪 gap 步
while j >= gap and arr[j - gap] > key:
arr[j] = arr[j - gap]
j -= gap
arr[j] = key
# 这一轮大跨步排序完后,缩小步长
gap //= 2
return arr
# 测试
data = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(f"希尔排序后: {shell_sort(data)}")
希尔排序为什么牛?
当 gap = 1 的最后一轮开始时,整个数组已经宏观上基本有序了。而我们前面说过,插入排序在面对“基本有序”的数组时,时间复杂度会逼近 O(n)!希尔排序巧妙地利用了插入排序的这个隐藏天赋。它的时间复杂度打破了 O(n^2) 的魔咒,根据步长序列的不同,可以达到 O(n^{1.3}) 甚至 O(n * log^2 *n)。
总结对比
| 算法 | 找位置的方式 | 挪位置的步幅 | 时间复杂度 | 核心意义 |
|---|---|---|---|---|
| 普通插入排序 | 从右向左线性找 | 每次 1 步 | O(n^2) | 基础,对近乎有序数组极快。 |
| 折半插入排序 | 二分查找 | 每次 1 步 | O(n^2) | 减少了比较次数,但挪动次数没变。 |
| 希尔排序 | 跨分组线性找 | 大跨步跨越 (gap) | 突破 O(n^2) | 大幅减少了极端逆序情况下的挪动次数。 |
🔔 直接看提示词
如果你觉得上面的你都没看懂,或者太长不看。可以直接到这里。复制一下提示词。
什么是插入排序?请给我一个最常见的实现。
插入排序有什么优化写法?请浅显易懂抽丝剥茧的给我讲述一下优化写法。
xxxx这个写法能否有具体的例子给我一步步的讲解一下,包括代码的难点。
我想知道这个代码为什么不可以是xxxx